Special Features: Behind the Scenes with NVivo
Project Overview
Background: RaceFail '09
Findings: Participants
Keyword Case Study: Black and White
Challenges and Future Applications
Special Features
Special Features
So I thought it might be fun to see what all this stuff looks like mid-process. Below are some screencaps of what my NVivo file looks like. I'm not advocating that this is what it should look like, but that's the fun part about experimentation.Part One: Files
The first image is a screenshot of all the files I imported into NVivo--note the posts split into two files, OP and comments. Originally, I used NCapture to import files directly from my browser, but this proved problematic, given the structure of LiveJournal posts with multiple pages of comments. In order to avoid duplicating the OP for each comments page, I instead copy-and-pasted the post into to separate Word docs.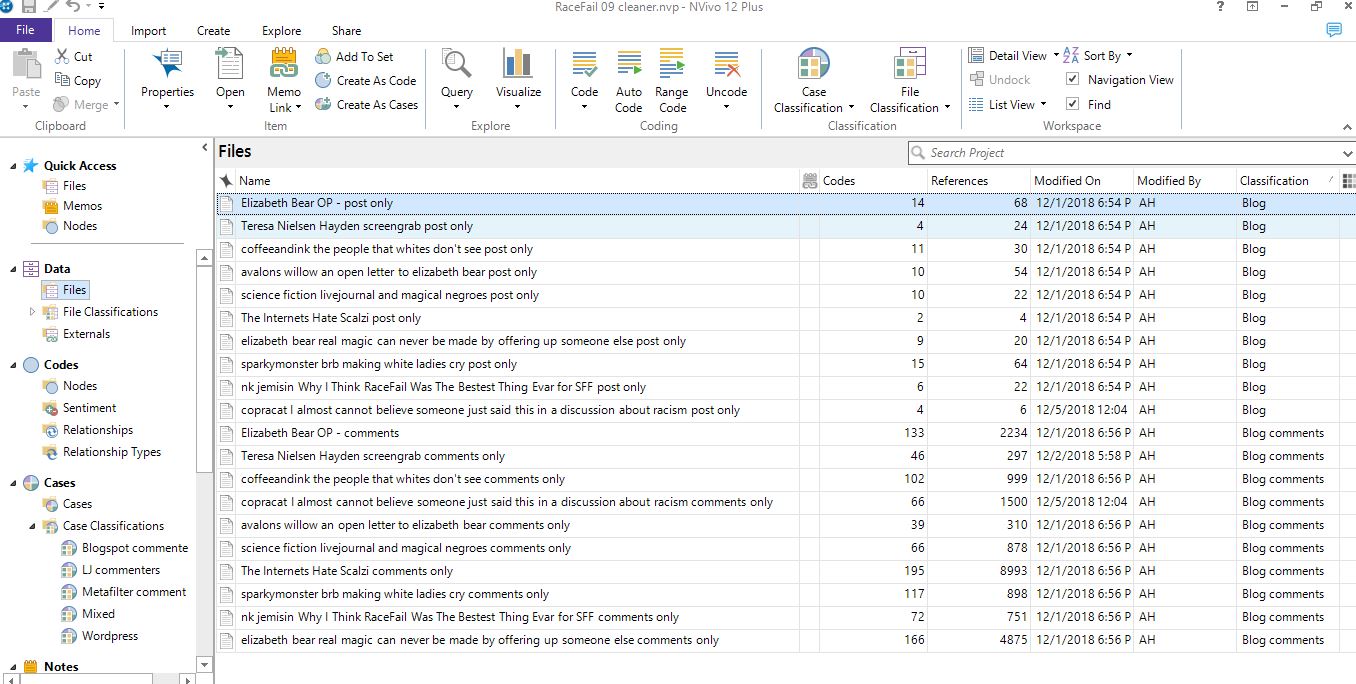
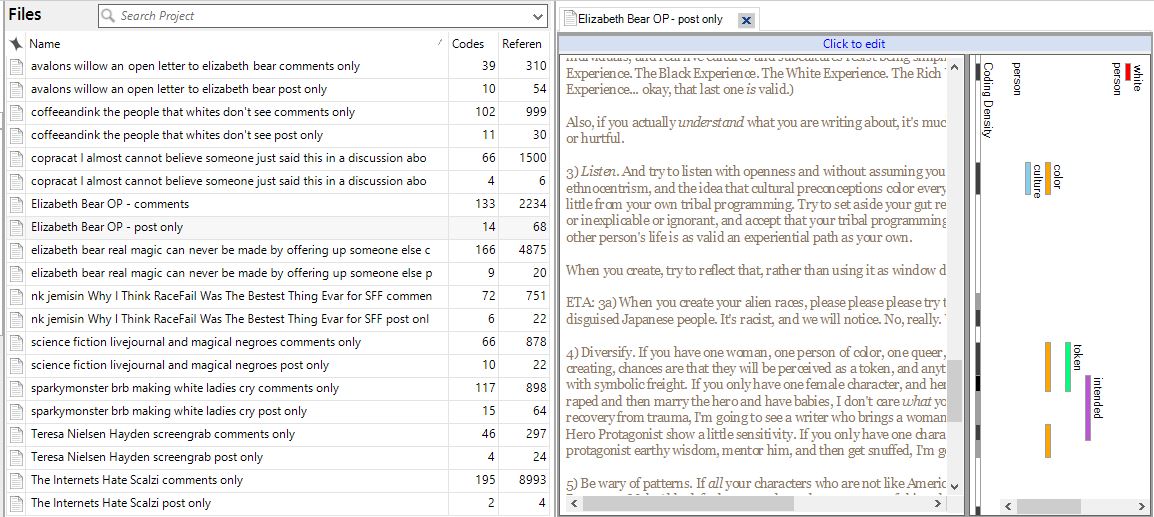
Next up is a close-up of Elizabeth Bear's OP (no comments). To the right of her post is a visual representation of the words I've coded for in color, and the code density in black and white (NVivo calls these coding stripes, and they're really nifty.)
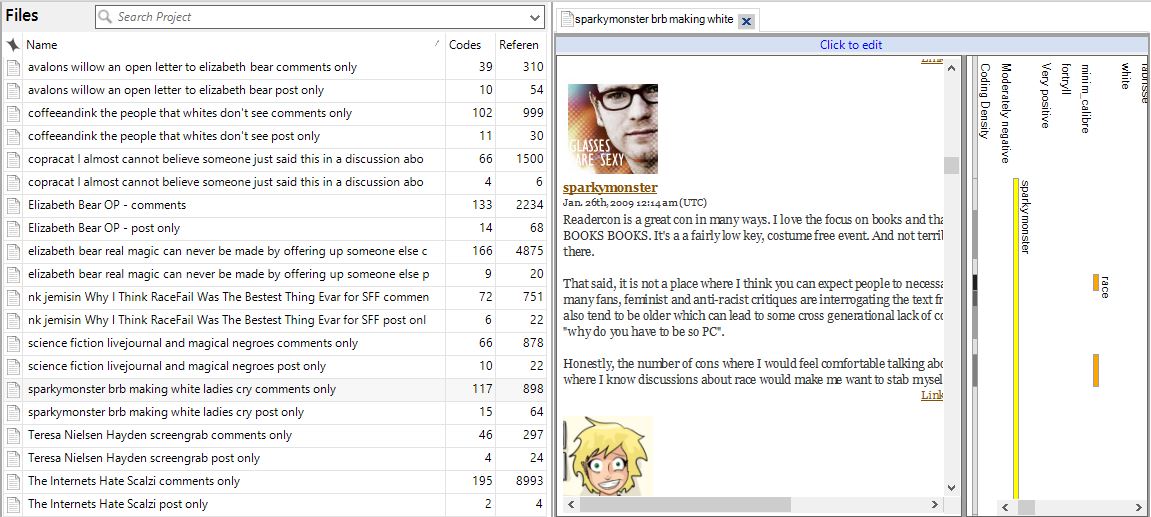
Here's what coding stripes look like with one of the comments posts--this one is from sparkymonster's post. Note that it's also coding for users based on each comment. This actually got me into a little bit of trouble, as the sheer amount of posters bogged down my system more than a little. I'm not sure whether that's an issue with my machine (it tries!) or whether I just went too far with the coding.
Part Two: Codes
Speaking of coding, here's a screenshot of some of the keywords I coded for. This list is a mix of words I'd preselected before uploading files and words that resulted from the frequently-used query.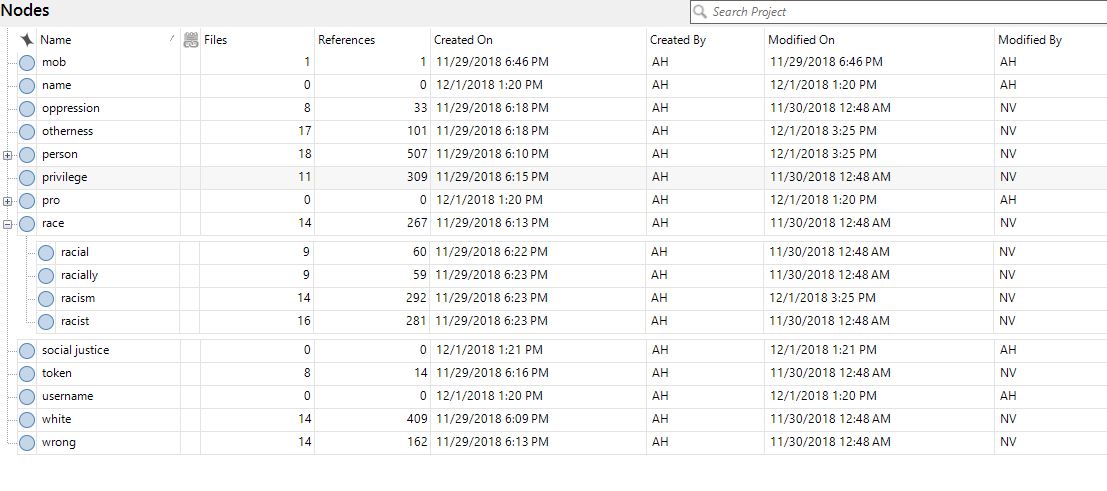
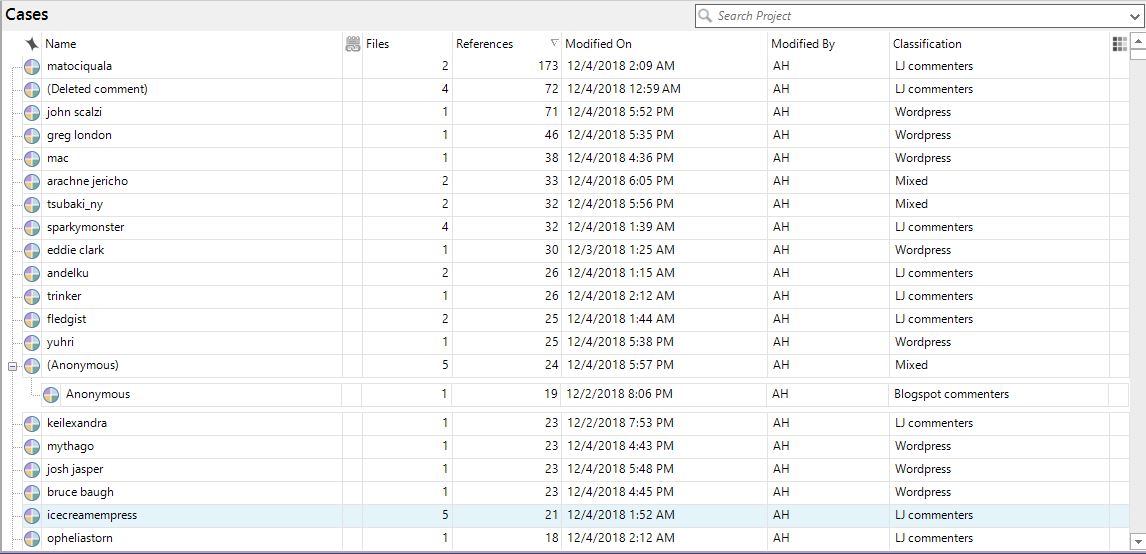
And here are some of the usernames (so, so many usernames) I saved--NVivo suggests these be saved under Cases, which is what I ended up doing. "Files" shows how many files they appear in, "References" shows how many times they appear in total, and "Classification" shows the type of file from which they were originally taken. Note that there is some crossover between websites, which you can see in the "Anonymous" tag. Avalon's Willow is a good example of this, as she appears on LJ and her blog. She gets tagged similarly to Anonymous.
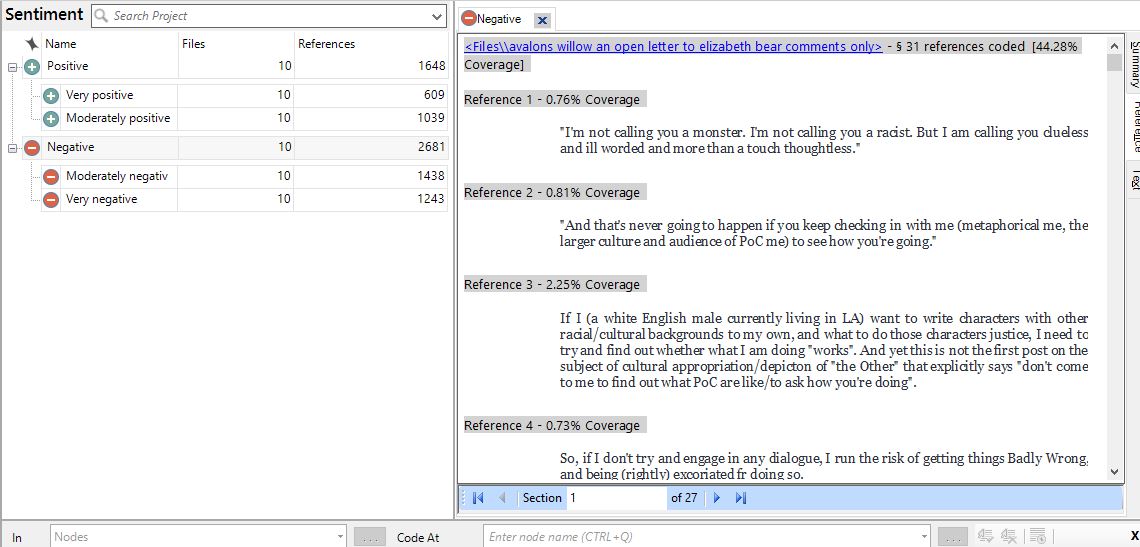
Finally, we have Sentiment, which is something I coded for but ultimately did not use. Sentiment is a nifty NVivo feature that pores over files and determines whether their tone is positive or negative (and to what extent). There are, of course, limitations to this, most notably that it cannot detect sarcasm (as a pop-up immediately tells you). You can tweak Sentiment to better suit your purposes, which is something I will likely do in future, given how important perceptions of tone were throughout RaceFail '09. For now, here's a screencap of overall instances of positive and negative sentiment to the left, and a close-up of Avalon's Willow's comments page to the right.
Part Three: Queries
Finally, here's a screencap of the queries I saved to my project. These are all the same type of query, showing word frequency for each of the comments files. I chose not to create queries for the OP files at this time, but I will likely do this in the future to show the difference between language in OPs and comments sections (which can be stark, as anyone who's been to YouTube lately can tell you).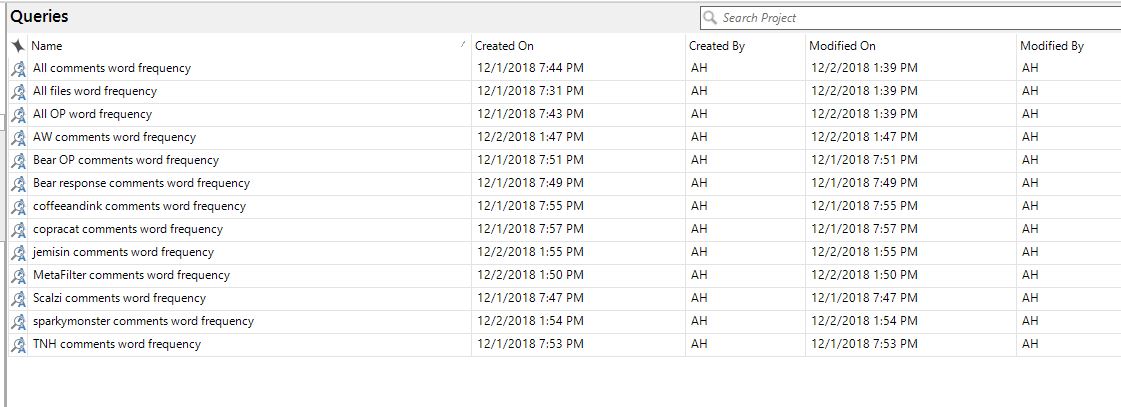
And that's it! Thanks for visiting the Special Features section. There will be no post-credits scene this time, but the Avengers will return in 2019...